Your Microphone Array Retains Your Identity
本文最后更新于:2022年12月14日 晚上
[Title]
Your Microphone Array Retains Your Identity: A Robust Voice Liveness Detection System for Smart Speakers
[Conference]
31st USENIX Security Symposium (USENIX Security 22)
1 Introduction
智能音箱已经是智能家居的控制枢纽,所以攻击它,很危险:
- replay attack
flaws in smart speaker
- inaudible ultrasound-based attacks
- deep learning models
研究者将这些攻击归结于真人和电子设备发出声音的区别,把这个特征称为 liveness。现有的liveness-detection 分为两种:
multi-factor authentication
利用音频和其他物理量(加速度、电磁场、超声波、WIFI、mm-Wave)区分人声和机器合成声
passive scheme
只利用音频。因为真人与机器发音方式的差异会导致音频频谱图中细微但显著的差异
仍面临的挑战 usability efficiency:
- 为了获得物理量信息,用户需要佩戴传感器(加速度、电磁场)或者主动发射信号(超声波、WIFI)
- 只利用音频的话容易受到声音传播信道变化的影响和基于频谱调制的攻击
- 为了保证鲁棒性需要用户保持固定的姿势
所以,一个好的liveness detection应该具备以下条件:
- Device-free
- Resilient to environment change
- High accuracy
Motivation: 主流智能音箱的麦克风阵列,由于麦克风的位置和相互距离不同,将显著增强收集音频的多样性,进而实现 device-free, robustness, accuracy
Key challenges:
- 1: What is the advantage of adopting a microphone array compared with a single microphone?
- 2: How can we eliminate the distortions caused by environment factors by leveraging the microphone array?
- 3: How can we demonstrate the effectiveness and accuracy of the proposed scheme?
2 Preliminaries
2.1 Threat Model
voice spoofing attack 语音欺骗攻击可分为两类:
Classical replay attacks
是本文主要研究的
Advanced adversarial attacks
voice synthesized technique
modify the spectrum of audio
2.2 Sound Generation and Propagation
声音的产生和传播过程
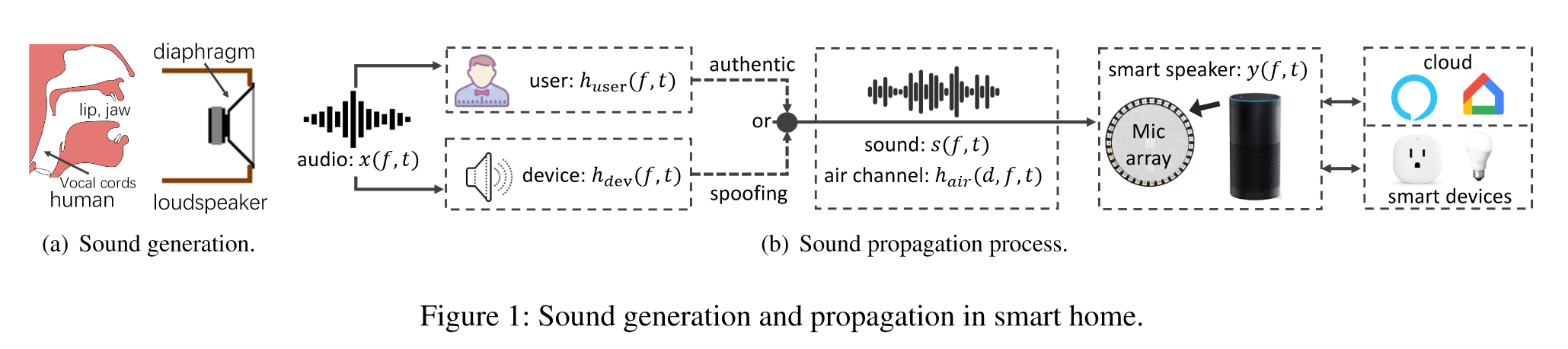
signal: $x(f,t)$
sound wave: $s(f,t)=h_{dev}(f,t)\cdot x(f,t)$
air pressure: $y(f,t)=h_{air}(d,f,t)\cdot s(f,t)$
$f$ —— 频率
$t$ —— 时间
$h_{dev}()$ —— 调制声音信号中的信道增益
$d$ —— 麦克风和声源的距离
$h_{air}()$ —— 声音信号在空气传播中的信道增益
2.3 Passive Liveness Detection
2.3.1 Mono Channel-based Detection
忽略声音传播过程中的失真,$h_{air}(d,f,t)$ 可以被看作一个常量$A$
约掉相同的项,接收到的音频已经包含了声源的身份信息
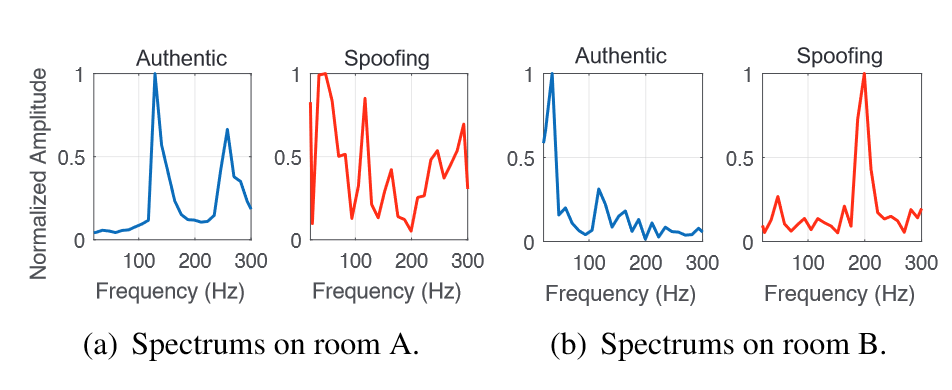
两个音频样本的sub-bass区(20-300Hz)有很大不同
但是,$h_{air}(d,f,t)$在不同环境下会受影响(周围物体的形状、材质,声音传播路径,空气吸收指数),不能一直被视作一个常量
2.3.2 Fieldprint-based Detection
不同声源会在其周围形成一个独特的声场,通过测量这个场的特性,可以推断出声源身份
但是,如果要获得稳定准确的声场信息,需要声源和传感器相对稳定
3 Array Fingerprint
RQ1: How can we model the sound propagation in smart speaker scenarios and answer why existing features (e.g., fieldprint) cannot be effective in such scenarios?
RQ2: How can we extract a useful feature from multichannel voice samples that is robust regarding a user’s location and microphone array’s layout?
RQ3: What are the benefits of the array fingerprint? Is it effective and robust to the distortions caused by environmental factors?
3.1 Theoretical Analysis on Sound Propagation for Smart Speakers
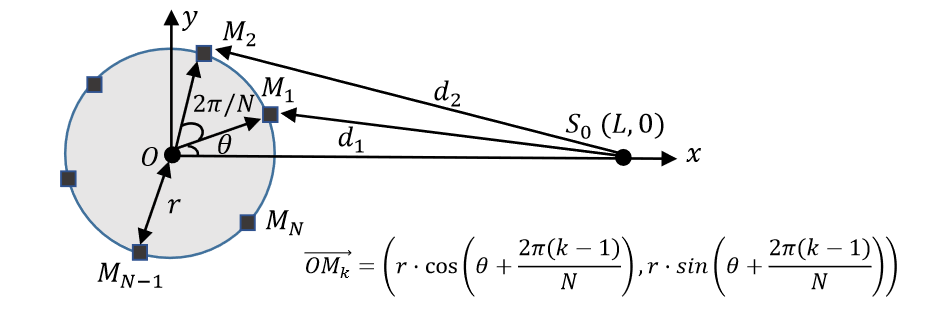
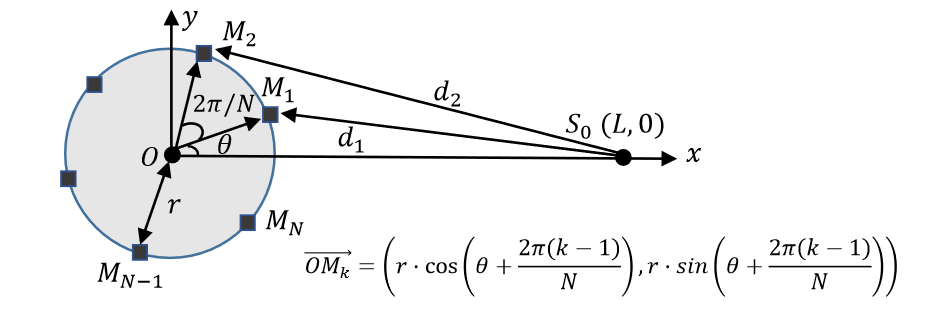
声源$S_0(L,0)$
麦克风阵列圆形分布$M_k$
应用经典的球形声波传播模型
那么第k个麦克风处的收集到的音频信息为
mono channel-based detection的缺陷
观察该式,发现声源与麦克风的距离的变化对结果的影响是非线性的,所以位置的变化带来的失真很难被消除
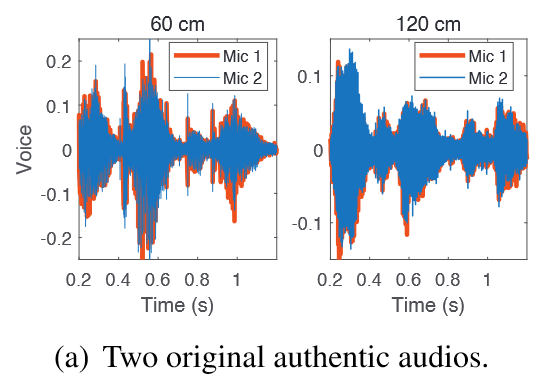
figerprint-based detection的缺陷
代入先前的式子得
当麦克风的相对位置固定时,$d_i-d_j$ 可以看作是常量;当不固定时,使用这种方案变得不可行
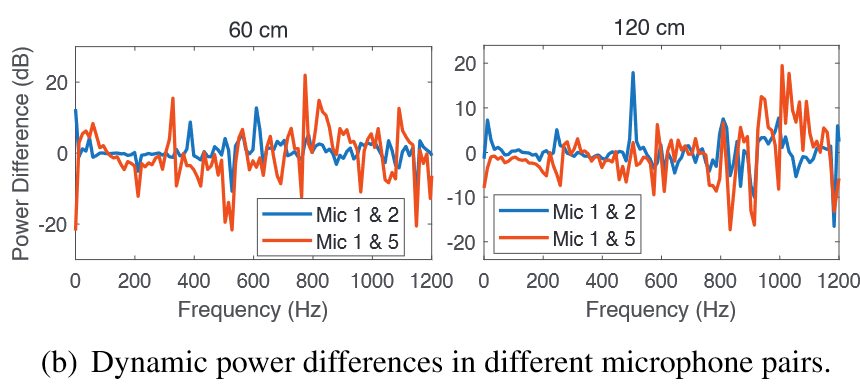
3.2 Advantage of Array Fingerprint: Definition and Simulation-based Demonstration
array fingerprint的定义如下:
最终array fingerprint只与声源音频和传播距离的标准差相关
为了从$s(f,t)$ 获得声源的身份信息,$\sigma_d$ 必须是常量,下面证明它
然后使用 $r=5cm$ 的Amazon Echo 3rd Gen音箱进行模拟
$L\in[1m,3m], \theta\in[0,90], N\in\{2,4,6,8\}$ 时的$\sigma_d$
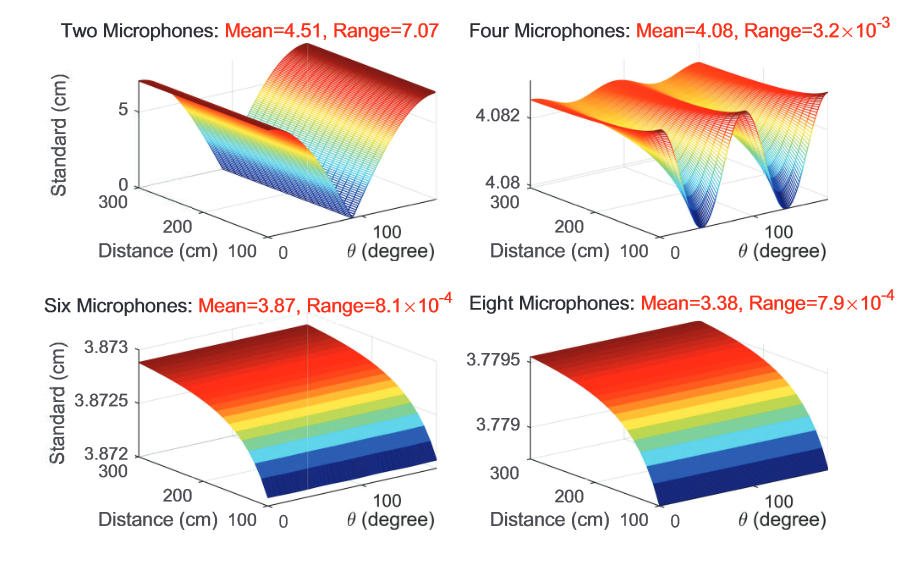
观察上图,当N超过4个之后,$\sigma_d$ 会趋向一个常量
而实际中智能音箱的麦克风通常多于4个,所以$\sigma_d$ 是几乎不变的,可以将它视作一个常量,几乎不影响array fingerprint
综上,array fingerprint只与声源音频$s(f,t)$ 有关,而且对环境因素的变化适应性强
3.3 Validation of Array Fingerprint
通过一系列的真实案例研究证明array fingerprint的有效性
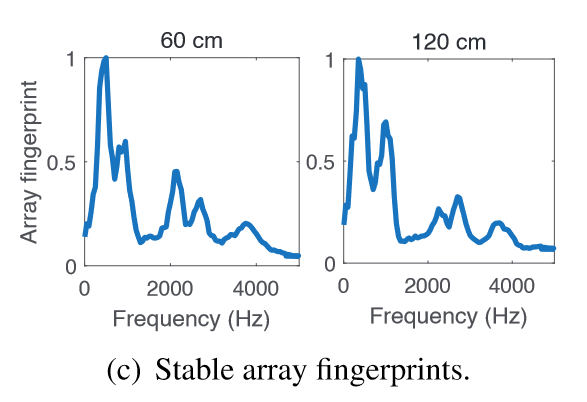
show the distinctiveness
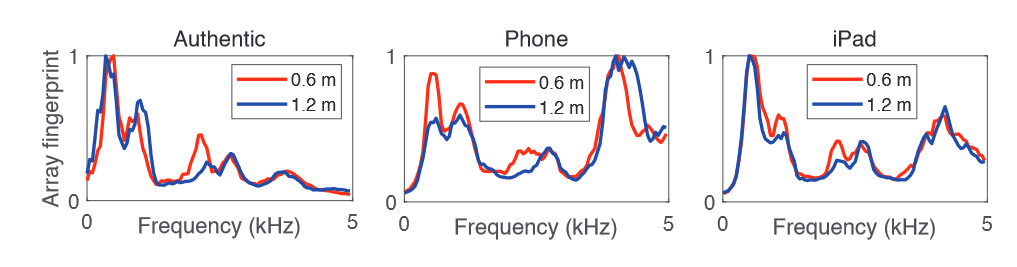
4 The Design of ARRAYID
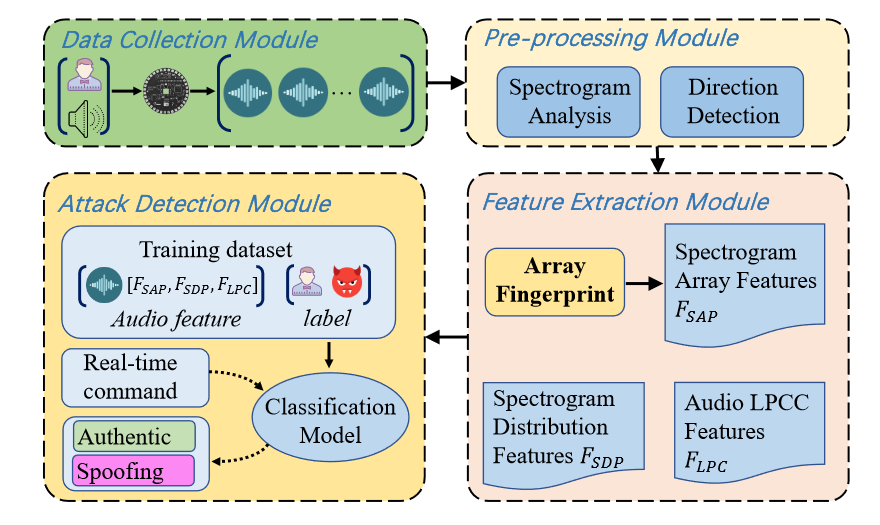
4.1 Multi-channel Data Collection
使用开放的带有语音接口的模块化开发板收集数据
send $V$ to the next module
4.2 Data Pre-processing
频率分析$s(f,t)$
STFT 短时傅里叶变换+FFT快速傅里叶变换
傅里叶变换FT不适合处理非平稳信号
所以——加窗,把整个时域过程分解成无数个等长的小过程,每个小过程近似平稳,再傅里叶变换,就知道在哪个时间点上出现的频率了——短时傅里叶变换
方向检测
找到离声源最近的麦克风
100Hz的高通滤波器
找alignment error最小的
$E_i=mean((V(:,i-1)-V(:,i))^2)$
4.3 Feature Extraction
4.3.1 Spectrogram Array Feature
只保留低于$f_{sap}=5kHz$ 的频率分量
采样率$F_s=48kHz$
FFT点 $N_{fft}=4096$
那么保留下来的频谱图$Spec_k=S_k(:M_{spec},:)$
$M_{spec}=[\frac{f_{sap}\times N_{fft}}{F_s}]=426$
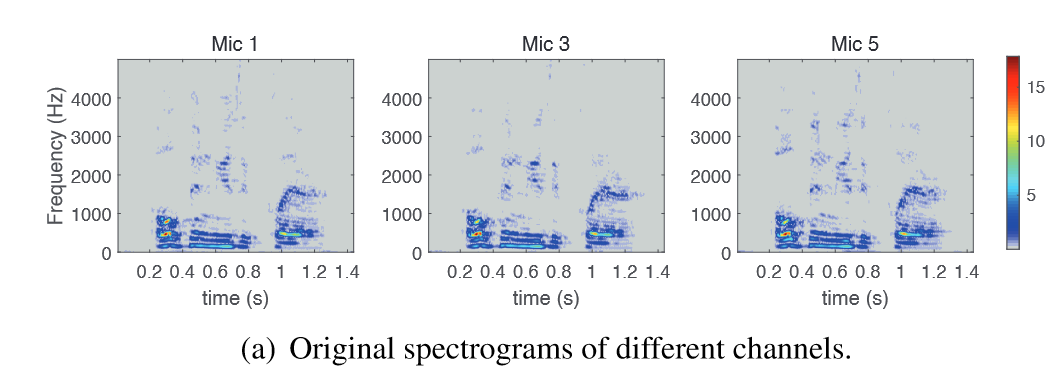
然后将$Spec_k$ 转为网格矩阵$G_k$
就是求每一块网格区域的总和
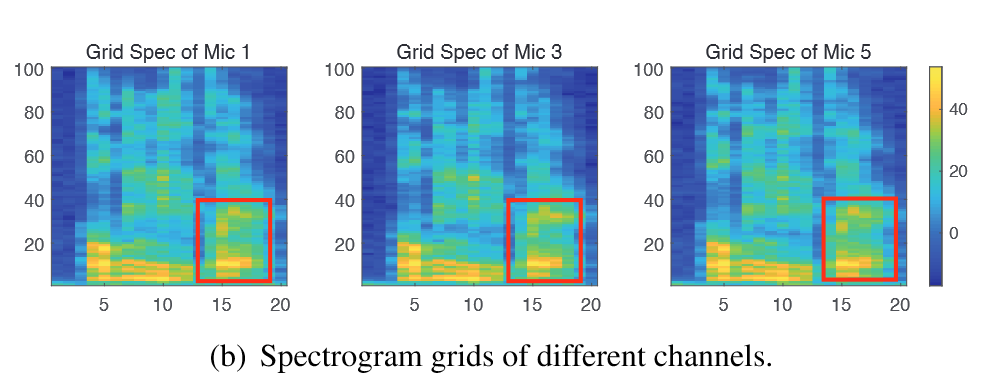
然后计算array fingerprint
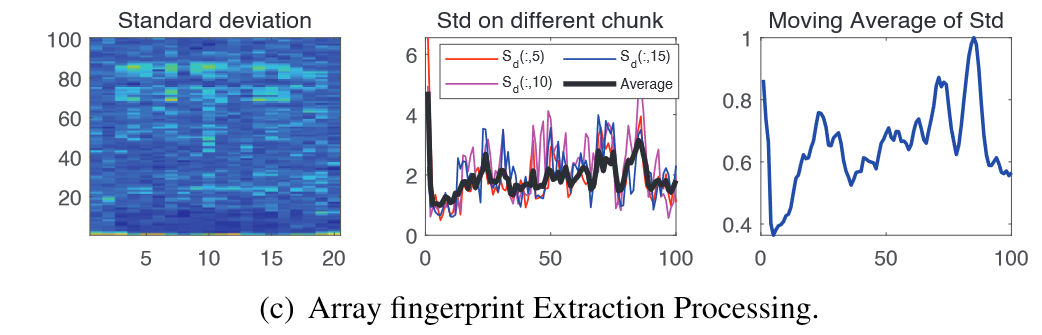
但是观察到$F_G(:,i)$ 不同,是因为人本身讲不同音节时的发声部位不同
为了获得持续时间中某人声的通性,在时间域上取均值$\overline{F_G}$,5-point moving average and normalization 得到 array fingerprint $F_{SAP}$
一个有效性测试。因为需要快速实时响应,所以array fingerprint必须轻量化,所以将 $F_{SAP}$ 重采样为$N_{SAP}$ points
4.3.2 Spectrogram Distribution Feature
频谱图的分布特征 $F_{SDP}$
取均值并重采样到长度$N_{Ch}$
然后获得$CH_k$ 的分布,计算累积分布函数$Cum_k$
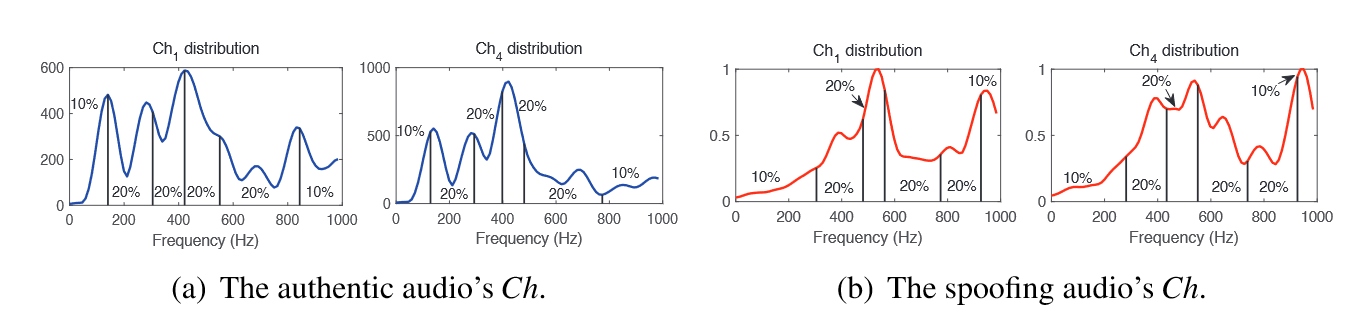
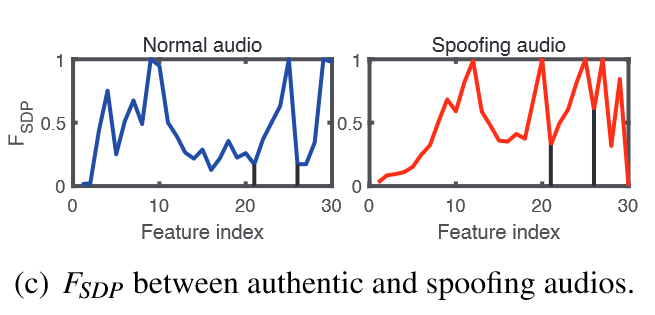
可以获得k组$N\times 5$指数$\mu$ ,再算均值和标准差
最终$F_{SDP}=[\overline{Ch},D_{mean},D_{std}]$
4.3.3 Channel LPCC Features
Linear Prediction Cepstrum Coefficients 线性预测编码倒谱系数
每个声道有自己的物理特性
$F_{LPC}$ 只保留最近的麦克风和它反面的麦克风的
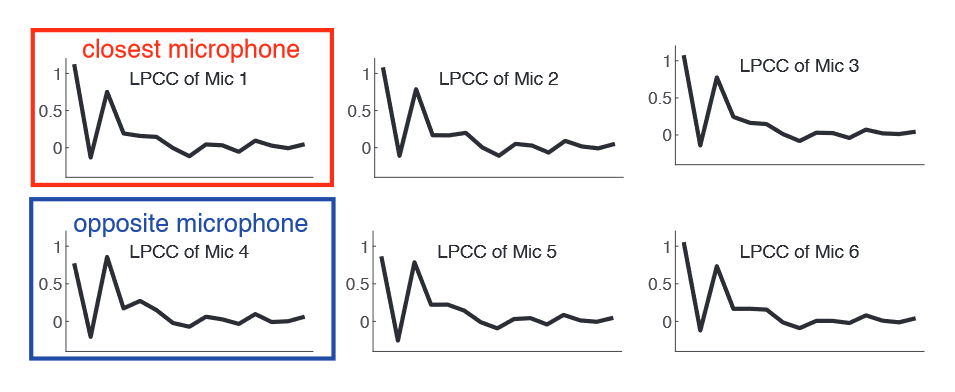
4.4 Classification Model
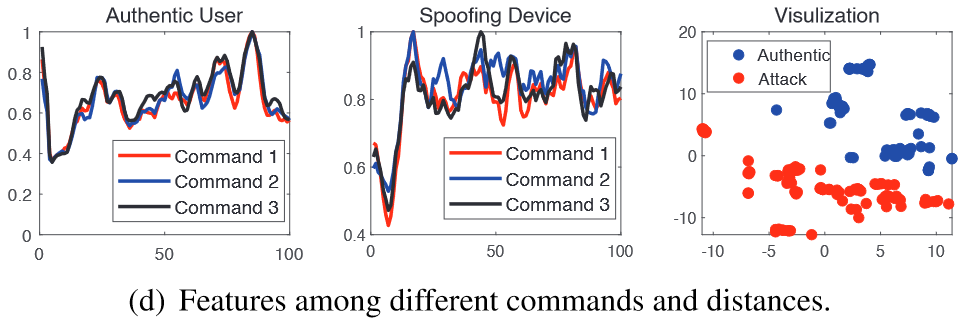
特征向量$X=[F_{SAP},F_{SDP},F_{LPC}]$
lightweight feed-forward back-propagation neural network
3 hidden layers (64, 32, 16) with relu activation5
5 Evaluations
5.1 Experiment Setup
Hardware setup
2 open modular development boards to collect multi-channel audios
- Matrix Creator: 8 microphones, r=5.4cm
- Seeed ReSpeaker Core v2: 6 microphones, r=4.7cm
14 different electrical devices as spoofing devices
Data collection procedure
20 participants
20 different voice commands, 4 distances
- Authentic audio collection
- Spoofing audio collection
Dataset description
MALD dataset: 32780 audio samples
Training procedure
train ARRAYID: two-fold cross-validation (the training and testing datasets are divided equally)
50% for generating a classifier
30% for validation
Evaluation metrics
accuracy
the percentage of the correctly recognized samples among all samples
false acceptance rate (FAR)
the rate at which a spoofing sample is wrongly accepted by ARRAYID
false rejection rate (FRR)
the rate at which an authentic sample is falsely rejected
true rejection rate (TRR)
equal error rate (EER)
the rate at which FAR = FRR
5.2 Perfomance of ARRAYID
Overall accuracy
accuracy = 99.84%
FAR = 13/22539 = 0.05%
FRR = 40/10241 = 0.39%
ERR = 0.17%
Per-user breakdown analysis
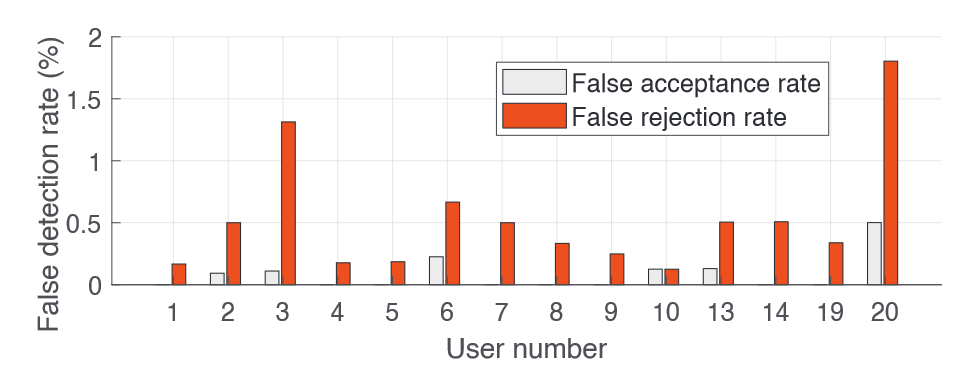
False Acceptance cases only exist in 6 users
False Rejection cases are distributed among 14 users
But even for the worst-case, the detection accuracy is still at 99.0%
Time overhead
Intel i7-7700T CPU, 16 GB RAM
6-channel audios: 0.12s
8-channel audios: 0.38s
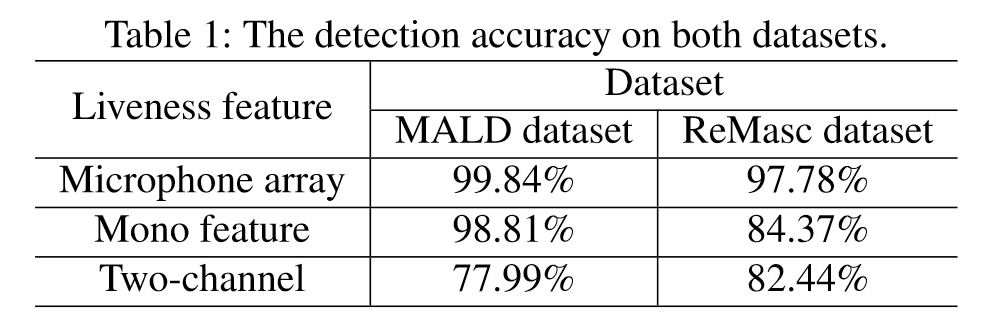
Comparison with previous works
To eliminate the potential bias in MALD dataset
ReMasc Core dataset: 12023 voice samples, 40 users, indoor/outdoor/vehicle environments
5.3 Impact of Various Factors on ARRAYID
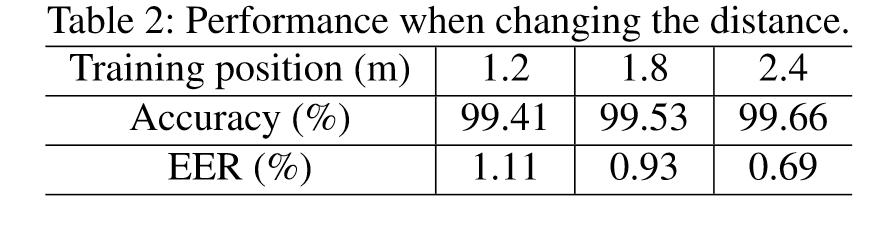
Impact of changing distance
3 participants, 3 locations (1.2m, 1.8m, 2.4m)
train test 使用 different distances
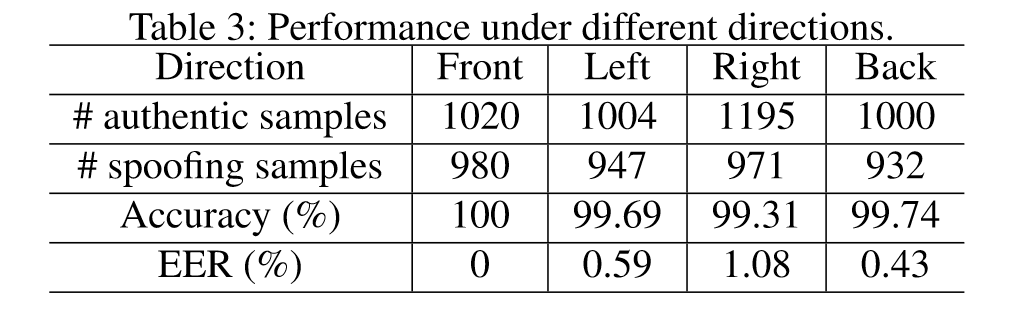
Impact of changing direction
10 participants, 4 directions (front, left, right, back)
Impact of user movement
speak/hold a spoofing device while walking
detection accuracy = 98.2%
Impact of changing environment
launch voice spoofing at a different room
detection accuracy = 99.30%
Impact of microphone numbers in the smart speaker
从Matrix的8-channel数据抽出$(M_1,M_3,M_5,M_7)$ 新生成4-channel audio data
after conducting two-fold cross-validation on each group, the detection accuracies are:
4-channel = 99.78%
6-channel = 99.82%
8-channel = 99.90%
所以4以上的声道数量的变化影响不会很大,如同先前理论分析的一样
只要麦克风阵列呈圆形分布,ARRAYID就可以提供robust protection on thwarting voice spoofing
Impact of Spoofing Devices
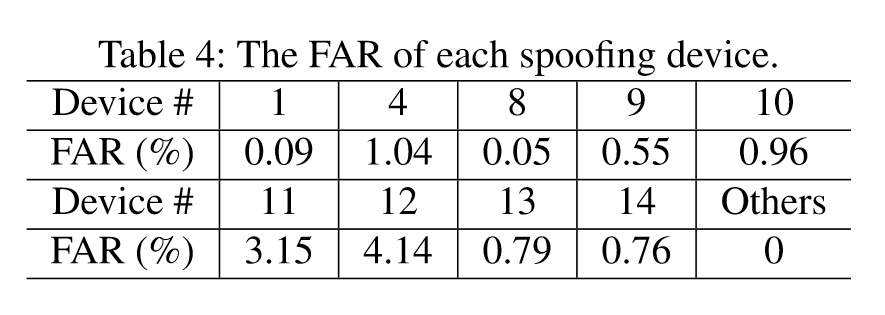
(👆 to reduce the user’s enrollment burden, set the training proportion as 10%)
100% detection accuracy on 5 devices
even in the worst case, the true rejection rate is still at 95.86%
5.4 Robustness of ARRAYID
5.4.1 Handling the Incomplete Enrollment Procedure
参与者需要参与authentic and spoofing 两个音频样本的收集。考虑到参与者没有完整参与的情况:
Case 1: handling users who did not participate in any enrollment procedure
对于MALD数据集中的每个用户,使用其他19个用户的所有样本来训练分类器,将该用户的样本作为测试集,结果精度及对比如下:
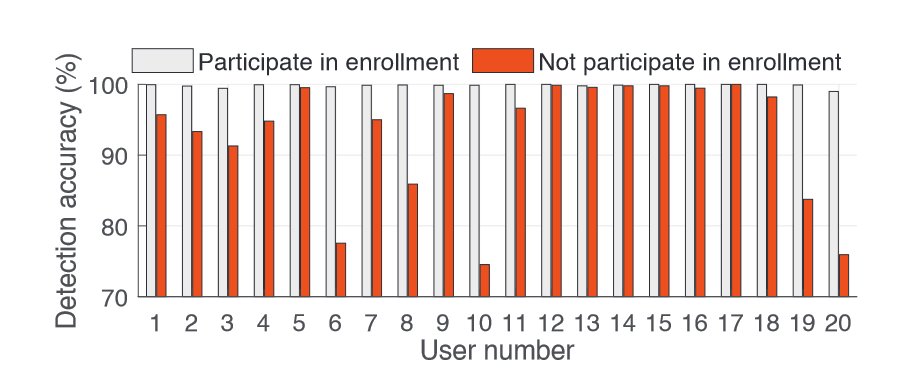
overall accuracy: 99.84% to 92.97%
the worst case: 99.87% to 74.53%
for 11 users: still higher than 95%
证明ARRAYID处理未知用户的能力不稳定
To be improved!
Case 2: handling a user with only authentic samples
选取MALD数据集中#1~#18,对每个用户,使用该用户的authentic和其他17个用户的spoofing来训练,使用该用户的攻击样本进行测试,通过计算相关指标(如TRR)来评估
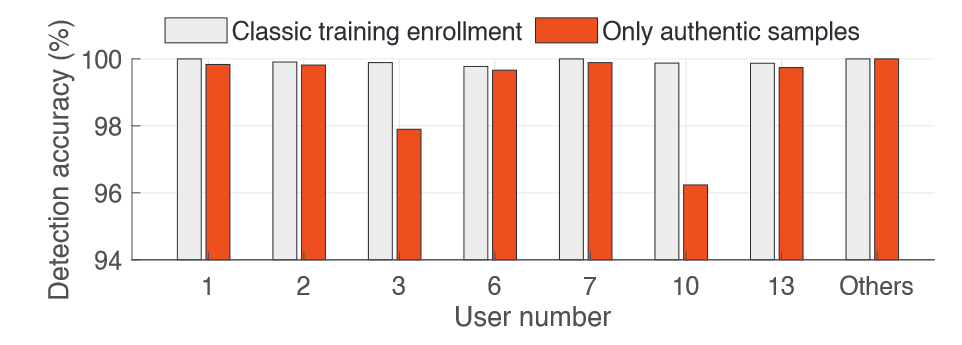
overall accuracy: 99.96% to 99.68%
for 11 users: remains 100%
for 7 users: above 96%
Effective!
5.4.2 Liveness Detection on Noisy Environments
the classifier where the noise level is 30 dB
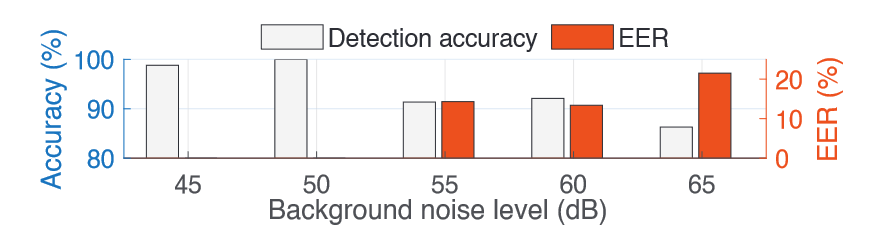
noise level from 45 dB to 65 dB: accuracy from 98.8% to 86.3%
work well when background noise < 50 dB
To be improved!
5.4.3 Defending against Advanced Spoofing Attacks
Thwarting modulated attacks
调制replayed audio的频谱:首先要获得目标用户的authentic voice samples;然后测量spoofing device的frequency amplitude curve和相关inverse filter;最后对authentic audio应用inverse filter并且通过spoofing device重放,收集到的频谱就会和authentic audio频谱相近。
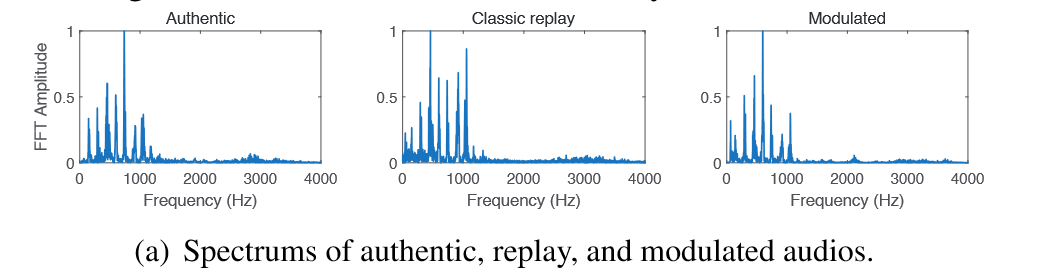
这种方法可以绕过许多现有的liveness detection,但是array fingerprints仍能显示authentic与modulated的不同。因为人和设备不能被视作点声源,我们的方案使用了多个麦克风收集音频
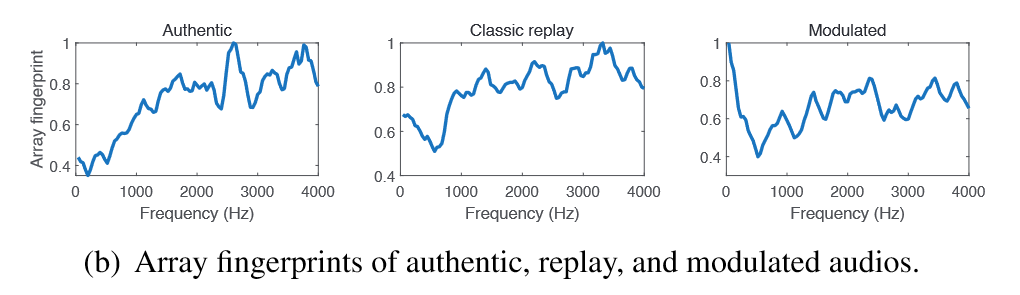
并且通过实验,生成了三个设备的modulated attack samples并应用分类器,准确率为100%, 92.74%, 97.29%
发现在不同设备上的表现有差距
To be improved! - combine ARRAYID with the dual-domain detection
Other adversarial example attacks
hidden voice attack / VMask
detects 100%
reason: these attacks only aim to add subtle noises into source audio
6 Discussions
6.1 User Enrollment Time in Training
Impact of training dataset size
To reduce the user’s registration burden
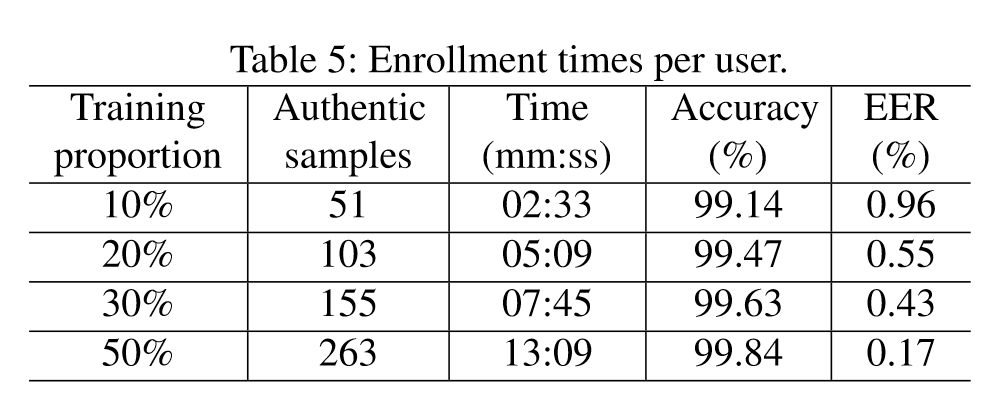
Time overhead of user’s enrollment
10% training proportion
each user provides 51 authentic samples
average time length of voice command < 3s
the enrollment can be done < 3m
is ACCEPTABLE in real-world scenarios
6.2 Distinguish between Different Users
select 250 authentic samples from 5 users
utilize t-SNE to reduce the dimension, the feature vectors from different users are visually clustered
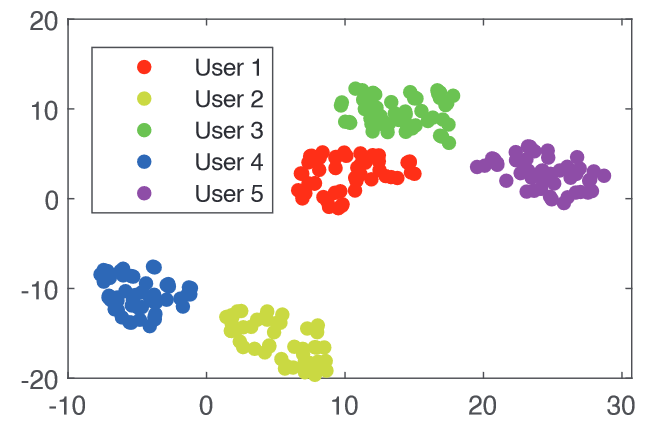
经实验,speaker recognition accuracy = 99.88%
6.3 Limitations and Countermeasures
The user’s burden on the enrollment
incorporate the enrollment into daily use
divide ARRAYID into:
working phase
collect the audio and save the extracted features
idle phase
automatically update the classifier
自动重训练可能会隐含其他风险
Impact of noise and other speakers
the strong noise or other speaker’s voice existing in the collected audios will inevitably degrade its performance.
Temporal stability of array fingerprint
the generated feature may be variant when the participant changes her/his speaking manner or suffers from mood swings
a feasible solution: daily use
本文作者: 31
本文链接: http://uuunni.github.io/2022/12/14/Your-Microphone-Array-Retains-Your-Identity/
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!